Looking into my gRPC transcoding project: larking . I recently benchmarked it against gRPC-gateway with some mixed results. Let's profile it and see if we can make it faster.
TLDR: Code changes are here with each commit showing a tried optimisation technique. I'll break down each method below.
Profiling
First step is to profile the benchmark. The test is a single HTTP GET call to retrieve a book by the resource path.
go test -bench=BenchmarkLarking/HTTP_GetBook -run="^$" -memprofile memprofile.out -cpuprofile profile.out
Using go tool pprof to investigate the results we can generate the following two graphs.
CPU
CPU is dominated by system calls. It is an E2E test to show what benefits would have in a semi-real setting, so system calls do make sense. It's not in parallel either, maybe something to add to benchmarking later.
Nothing stood out to me here. Let's continue onto the memory profile.
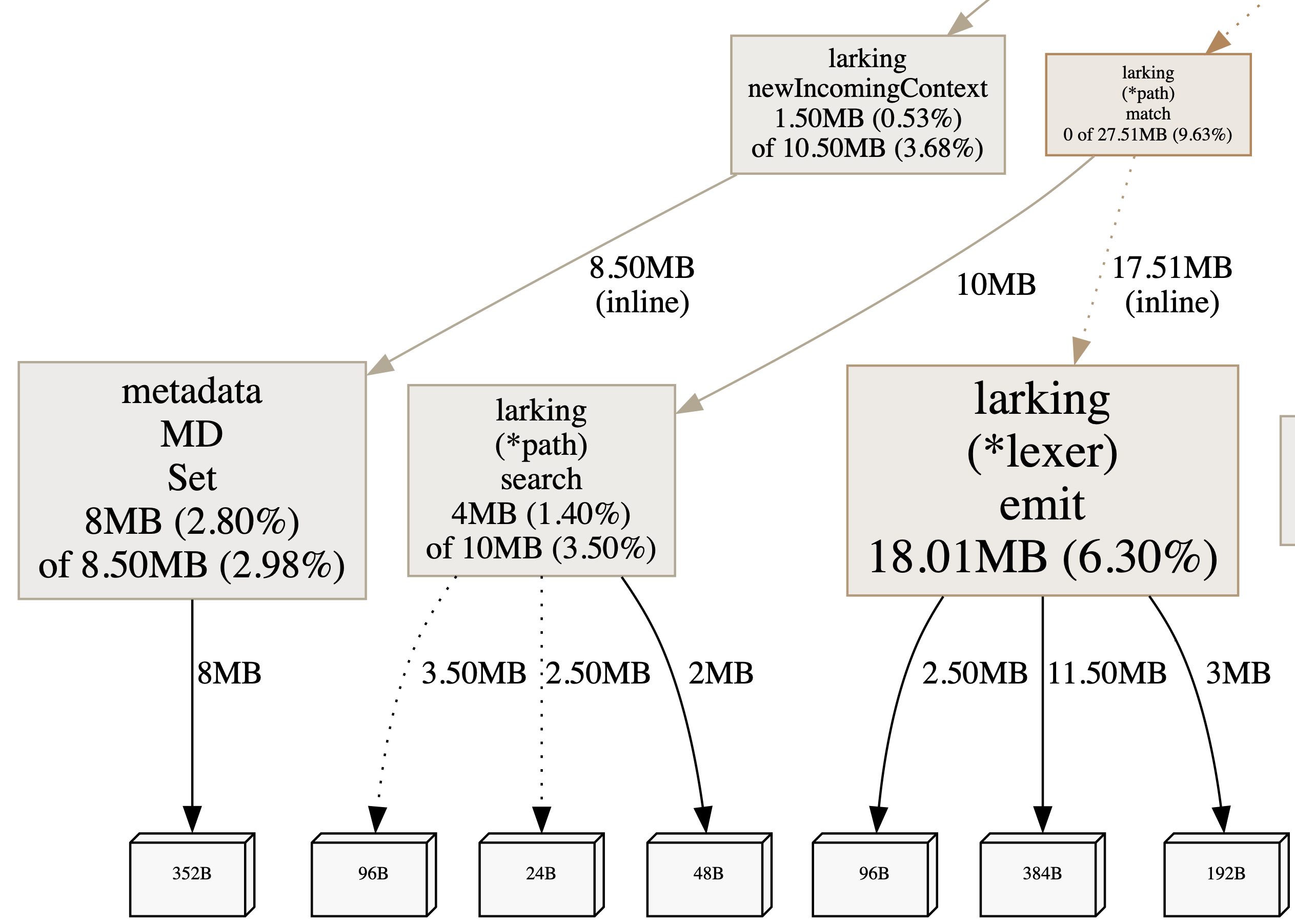
MEM
Memory is mostly setting up requests and encoding them over the network. We can expect encoding libs to be fairly well optimised. Focusing on the library, lexer.emit is our largest culprit. Each emit call allocates a token to the array of tokens. Let's start here and see how we go.
To make sure our changes are making a difference, let's measure the initial conditions. Here's the starting numbers to beat:
55613 ns/op 10200 B/op 159 allocs/op
About the lexer
The library needs to understand HTTP paths to map requests to the correct service method. It uses a handwritten lexer to generate tokens for the http.proto syntax. It was originally based on Rob Pike's lexical scanning talk. His lexer has an emit function that sends a token on a go-routine, the lexer never needs to return to emit a token meaning the state can be maintained between emit functions.
Goroutines allow lexer and caller (parser) each to run at its own rate, as clean sequential code. Channels give us a clean way to emit tokens.
Goroutines are cheap, but still not free. I didn't want to start a concurrent process to parse what could be a small path. Interestingly, I'm not sure if ever benchmarked what the cost of this method was. Instead, when the lexer calls emit we append it to a list of tokens, running the lexer to completion before the parser continues.
Improvements
Slice of bytes
My first attempt looking at the lexer input was to use []byte references for the token values and input. Immediately trying this made it slower. The conversion of the string route to bytes now caused an allocation, and building back to strings caused more inefficiencies.
A faster lexer in go is a great breakdown about the speed benefits of sub slicing strings. I think I had looked at this blog post before but had forgotten why I had chosen strings over bytes, oh well. What next?
Sync pool
Pools can be used to cache allocated items for reuse reducing strain on the garbage collector. I wanted to reuse the *lexer to keep allocated tokens for the next call. The thinking was we could amortise the allocations cost over multiple clients. Testing this in a small local benchmark proved promising. Allocations went to zero and we halved the time per operation.
Looking into the E2E benchmark however only saved 1 allocation; 😅. Small improvements in speed and bytes but within error margins (maybe I closed a tab or two). Sync pool is also rather dangerous to use. Most implementations need a way to group the size of objects to avoid attacks where a client could force large allocations to be pinned to the pool and never be freed. This github issue goes into the details and other concerns with using sync.Pool. Thinking about the size issue led me to the next solution.
55215 ns/op 9473 B/op 158 allocs/op
Fixed array
The number of tokens should be limited to avoid wasting time processing requests with large paths. We use the lexer for both generating the bindings and parsing the requests. Which means, valid requests will have less tokens than the path template bindings. HTTP path limits seem to be around 32K characters, but the general recommendation is 2K characters. The test path for the benchmark /v1/books/1/shevles/1:read comes out at 13 tokens at 26 chars. In this case ID's are only 1 char, if we assume uuids thats 96 chars ~ 8 chars per token. I chose a limit of 64 tokens which should give path sizes of around 512 chars. Local benchmark testing showed doubling the token limit to 128 would only add a small bump in op/s. Hopefully 64 tokens is all that will be needed though.
Now we have a token limit we can allocate an array of tokens. This keeps the memory bounded and allows it to be stack allocated. Running the build with: go build -gcflags="-m" we can analysis if the lexer escapes to the heap.
./rules.go:742:7: &lexer{...} does not escape
Success, and benchmarking this we can see the reduced allocations! We removed all allocations in the lexer.
46666 ns/op 9363 B/op 154 allocs/op
Field alignment
Field alignment can reduce the size of structs by sorting the fields to remove needing offsets. This can have some nice wins for things like cache locality. Andrew Kelly's talk on Practical DOD is a great deep dive on applying many optimisations like this in Zig. Go has a tool fieldalignment to analyse libraries and apply fixes.
handler.go:19:14: struct with 40 pointer bytes could be 32
lexer.go:75:12: struct with 1560 pointer bytes could be 1536
mux.go:78:17: struct with 80 pointer bytes could be 56
mux.go:146:10: struct with 112 pointer bytes could be 104
mux.go:202:15: struct with 40 pointer bytes could be 32
mux.go:612:17: struct with 192 pointer bytes could be 152
rules.go:40:15: struct with 48 pointer bytes could be 32
rules.go:56:11: struct with 48 pointer bytes could be 32
rules.go:132:13: struct with 104 pointer bytes could be 88
rules.go:417:12: struct with 40 pointer bytes could be 32
server.go:179:20: struct with 48 pointer bytes could be 24
web.go:43:16: struct of size 88 could be 80
websocket.go:17:15: struct with 104 pointer bytes could be 64
rules_test.go:39:9: struct with 32 pointer bytes could be 24
rules_test.go:205:12: struct with 48 pointer bytes could be 24
rules_test.go:213:13: struct with 136 pointer bytes could be 128
web_test.go:35:12: struct with 24 pointer bytes could be 16
web_test.go:58:13: struct with 112 pointer bytes could be 104
With field alignment we can go from 2504 total bytes to 2264, 10% less. Let's measure what benefit this has on the benchmark.
Tiny, within error margins but almost no effort to apply. Run the fieldalignment cmd with -fix to correct all instances.
46361 ns/op 9355 B/op 154 allocs/op
Conclusion
Comparing with bechstat we've got about 17% faster, with 8% less bytes and 3.5% less allocation (-5 allocations). The lexer is now stack allocated and fixed size.
goos: darwin
goarch: arm64
pkg: larking.io/benchmarks
│ bench_old.txt │ bench.txt │
│ sec/op │ sec/op vs base │
Larking/HTTP_GetBook-8 55.61µ ± ∞ ¹ 45.15µ ± ∞ ¹ ~ (p=1.000 n=1) ²
Larking/HTTP_UpdateBook-8 56.07µ ± ∞ ¹ 47.25µ ± ∞ ¹ ~ (p=1.000 n=1) ²
Larking/HTTP_DeleteBook-8 44.10µ ± ∞ ¹ 36.76µ ± ∞ ¹ ~ (p=1.000 n=1) ²
geomean 51.62µ 42.80µ -17.07%
¹ need >= 6 samples for confidence interval at level 0.95
² need >= 4 samples to detect a difference at alpha level 0.05
│ bench_old.txt │ bench.txt │
│ B/op │ B/op vs base │
Larking/HTTP_GetBook-8 9.961Ki ± ∞ ¹ 9.126Ki ± ∞ ¹ ~ (p=1.000 n=1) ²
Larking/HTTP_UpdateBook-8 12.00Ki ± ∞ ¹ 11.15Ki ± ∞ ¹ ~ (p=1.000 n=1) ²
Larking/HTTP_DeleteBook-8 8.275Ki ± ∞ ¹ 7.435Ki ± ∞ ¹ ~ (p=1.000 n=1) ²
geomean 9.963Ki 9.112Ki -8.53%
¹ need >= 6 samples for confidence interval at level 0.95
² need >= 4 samples to detect a difference at alpha level 0.05
│ bench_old.txt │ bench.txt │
│ allocs/op │ allocs/op vs base │
Larking/HTTP_GetBook-8 159.0 ± ∞ ¹ 154.0 ± ∞ ¹ ~ (p=1.000 n=1) ²
Larking/HTTP_UpdateBook-8 185.0 ± ∞ ¹ 180.0 ± ∞ ¹ ~ (p=1.000 n=1) ²
Larking/HTTP_DeleteBook-8 105.0 ± ∞ ¹ 100.0 ± ∞ ¹ ~ (p=1.000 n=1) ²
geomean 145.6 140.5 -3.54%
¹ need >= 6 samples for confidence interval at level 0.95
² need >= 4 samples to detect a difference at alpha level 0.05
Finally the memory graph shows the lexer node has completely disappeared. NewIncomingContext has also removed some allocations by sharing the slice array of headers between the http.Headers and md.Metadata.
Please let me know if you see any improvements! I'm sure there's more to be done.